This section includes some notes on the maximum likelihood routine. As in the section on writing models above, if a model has a p or log_likelihood method but no estimate method, then calling apop_estimate(your_data, your_model) executes the default estimation routine of maximum likelihood.
If you are a not a statistician, then there are a few things you will need to keep in mind:
NULL data.This example, to be discussed in detail below, optimizes Rosenbrock's banana function, 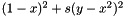 , where the scaling factor
, where the scaling factor 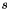 is fixed ahead of time, say at 100.
is fixed ahead of time, say at 100.
The banana function returns a single number to be minimized. You will need to write an apop_model to send to the optimizer, which is a two step process: write a log likelihood function wrapping the real objective function (ll), and a model that uses that log likelihood (b).
.vsize=2 part of the declaration of b on the second line of main() specified that the model's parameters are a vector of size two. That is, the list of doubles to send to banana is set in in->parameters->vector->data. more element of the apop_model structure is designed to hold any arbitrary structure of size more_size, which is useful for models that require additional constants or other settings, like the coeff_struct here. See Writing new settings groups for more on handling model settings. NULL apop_data set to the MLE settings in the .path slot, and it will be allocated and filled with the sequence of points tried by the optimizer. The problem is that the parameters of a function must not take on certain values, either because the function is undefined for those values or because parameters with certain values would not fit the real-world problem.
If you give the optimizer an unconstrained likelihood function plus a separate constraint function, apop_maximum_likelihood will combine them to a function that is continuous at the constraint boundary, but which is guaranteed to never have an optimum outside of the constraint.
A constraint function must do three things:
The idea is that if the constraint returns zero, the log likelihood function will return the log likelihood as usual, and if not, it will return the log likelihood at the constraint's return vector minus the penalty. To give a concrete example, here is a constraint function that will ensure that both parameters of a two-dimensional input are both greater than zero, and that their sum is greater than two. As with the constraints for many of the models that ship with Apophenia, it is a wrapper for apop_linear_constraint.
For convex optimizations, methods like conjugate gradient search work well, and for relatively smooth optimizations, the Nelder-Mead simplex algorithm is a good choice. For situations where the surface being searched may have several local optima and be otherwise badly behaved, there is simulated annealing.
Simulated annealing is a controlled random walk. As with the other methods, the system tries a new point, and if it is better, switches. Initially, the system is allowed to make large jumps, and then with each iteration, the jumps get smaller, eventually converging. Also, there is some decreasing probability that if the new point is less likely, it will still be chosen. Simulated annealing is best for situations where there may be multiple local optima. Early in the random walk, the system can readily jump from one to another; later it will fine-tune its way toward the optimum. The number of points tested is determined by the parameters of the simulated colling program, not the values returned by the likelihood function. If you know your function is globally convex (as are most standard probability functions), then this method is overkill.
estimate element, call apop_estimate to prep the model and run an MLE. 
